We beat GPT-5.4 at Tuvaluan.Now we're giving the hardware to Tuvalu.
Our 3B-active model outperformed GPT-5.4 on 6 of 7 Tuvaluan language tasks. We won an NVIDIA DGX Spark at GTC 2026 — and we're sending it to Tuvalu so 11,000 speakers can run their own sovereign AI agents in their own language.
342k
parallel pairs
Largest Tuvaluan-English corpus ever assembled
3B
active params
MoE fine-tuned on Tinker, 10x smaller than what we beat
6/7
task slices won
Translation, chat, QA, summarization vs GPT-5.4
3rd
place at GTC
SemiAnalysis Hackathon at NVIDIA GTC 2026
The result
3B parameters. Beats frontier models.
We built the largest Tuvaluan-English corpus ever assembled (342k pairs), trained a two-stage model on Thinking Machines' Tinker platform, and evaluated it against GPT-5.4, Claude Sonnet, Gemini, and Google Translate on 7 task slices.
Our model leads on 6 of 7. Specialization beats scale when the infrastructure is right.
Shared Tuvaluan benchmark (chrF++)
GTC 2026
3rd place. DGX Spark. Going to Tuvalu.
The SemiAnalysis hackathon at NVIDIA GTC 2026 challenged teams to build real AI systems, not demos. We placed 3rd and won an NVIDIA DGX Spark.
We're not keeping it. The DGX Spark is going to Tuvalu — so a nation of 11,000 people can run AI agents that speak their language, on their own hardware, under their own control. Sovereign AI starts with sovereign infrastructure.
Why Tuvalu
A country with 15 years left.
Tuvalu is a nation of 11,000 people spread across nine coral atolls in the Pacific. The highest point is 4.6 meters above sea level. At current rates of sea level rise, most of the country will be uninhabitable within 15 years.
When a country disappears, its language disappears with it. Tuvaluan has no backup — no large diaspora, no written literary tradition at scale, no presence in any major AI system. If the land goes underwater and the language has no digital infrastructure, it is gone forever.
That is why we chose Tuvaluan. Not because it was easy — it was the hardest possible test case. If we can build sovereign AI for a language this small, this endangered, and this invisible to frontier models, the playbook works for every language.
"We will not stand idly by as the water rises around us."
Simon Kofe, Tuvalu Foreign Minister — COP26, standing knee-deep in the rising sea
Tuvalu's foreign minister Simon Kofe addresses COP26 from the rising ocean. Over 1 million views. The world watched — then looked away.
Tuvaluan approved
Real feedback from real speakers.
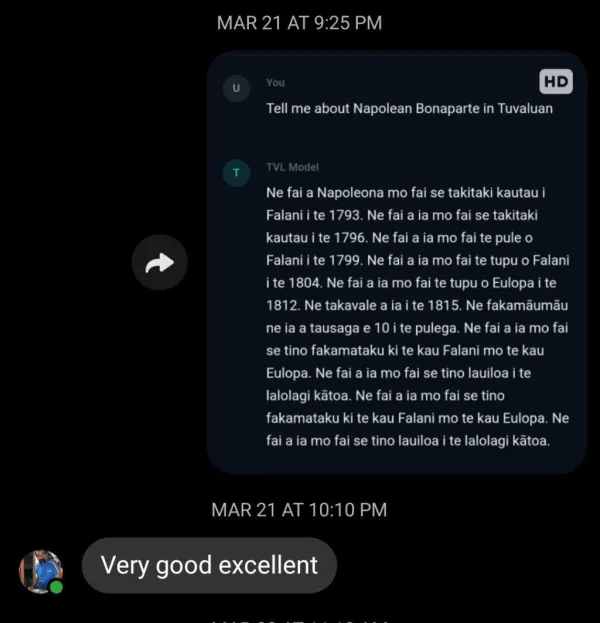
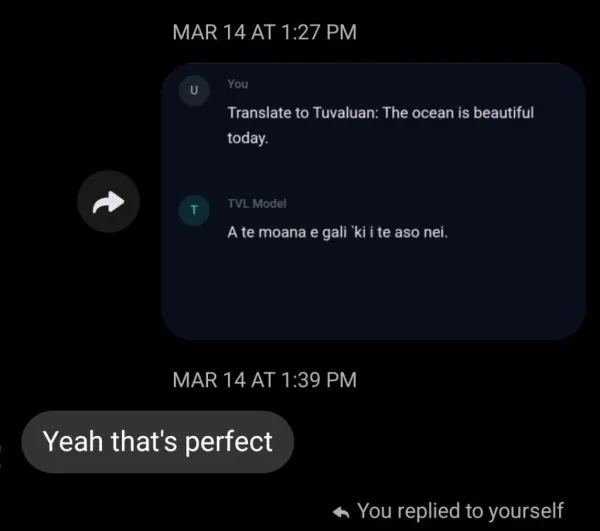
We don't just run benchmarks — we send our translations to native Tuvaluan speakers and ask them to judge. These are real text messages from community members reviewing our model's output.
"You got a very good training you learn Tuvalu by your self — Good Tecnology"
Explore the system
Everything is live and open
Benchmark
See the eval results
41.8 vs 36.1 chrF++ across 7 task slices. Interactive dashboard, per-model breakdowns.
Open →Live model
Talk to Tuvaluan AI
Try real-time code-switching between Tuvaluan and English.
Open →Product
Read Tuvaluan football news
Live translated articles from Goal.com, FIFA, and Sky Sports.
Open →Community
See the Kominiti dashboard
Real user feedback signals from across the Tuvaluan islands.
Open →On the ground
This work comes from a real place

Built with the community, not for them.

11,000 speakers. Nine atolls. One language to save.

Fieldwork means getting your hands dirty.

The entire country is 26 km². Smaller than Manhattan.

4.6 metres above sea level. That's the highest point.

Football is the language everyone shares. We started there.
What's next
The Language Lab
Preserving dying languages. Enabling sovereign AI.
Tuvaluan was the proof. Now we're building an open-source Language Lab — a nonprofit 501(c)(3) that gives endangered language communities the tools, models, and hardware to run their own AI systems.
The playbook is proven: build the corpus, train a specialized model, ship a real product, collect feedback, improve. We did it for Tuvaluan with 342k pairs and 3B active parameters. We're doing it next for the Pacific languages closest to disappearing.
First target languages
01
Open corpus infrastructure
Scalable pipelines for scraping, aligning, cleaning, and decontaminating parallel text for any low-resource language. Published to Hugging Face.
02
Community-owned models
Specialized models trained on community data, evaluated by native speakers, and deployed on community hardware. Not a cloud API — actual sovereignty.
03
Sovereign hardware
The DGX Spark goes to Tuvalu. Future hardware goes to future communities. AI agents that speak your language should run on your infrastructure.